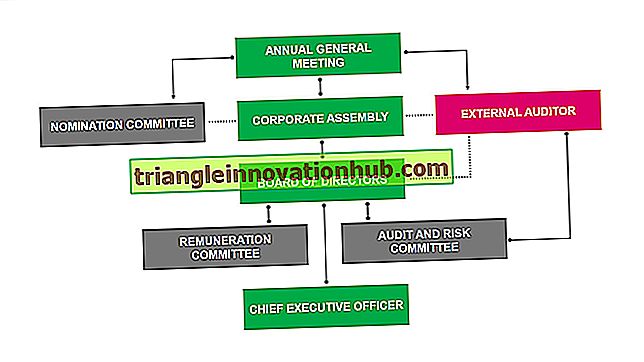
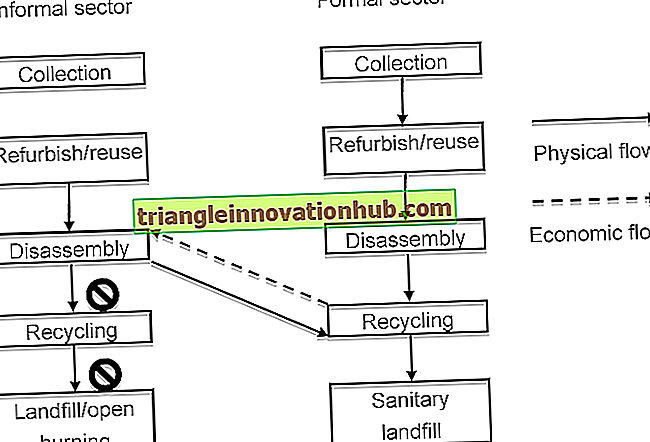
Problemi e procedure coinvolti nella selezione del lavoro
Prima di procedere all'esame dei modelli di selezione di base disponibili per lo psicologo, è necessario occuparsi di un breve sguardo al modello generale di previsione multipla. Questo modello viene in genere definito come il modello di regressione multipla. Nel paradigma di previsione generale sviluppiamo una linea di regressione per adattare l'insieme di punti dati definiti dai punteggi delle persone su un predittore (l'asse xo l'ascissa) e sul criterio (il asse y o ordinata).
La Figura 3.1 mostra una situazione del genere. La linea di regressione in Figura 3.1 è una linea retta e si trova in modo tale che la somma delle "distanze cave da ciascun punto alla linea (parallele all'asse y) sia la più piccola possibile. Usiamo una linea retta che meglio si adatta poiché abbiamo assunto una relazione lineare tra x e y.
La formula di base per una linea retta è
y = a + bx
Dove y = punteggio previsto per criterio
a = una costante che indica il punto in cui la linea di regressione incrocia l'asse y
b = pendenza della linea, rappresentata da Δy / Δx, o la variazione in y osservata per una variazione corrispondente in x
x = punteggio osservato sul predittore
Pertanto, il modello di linea di regressione di base appare come mostrato nella Figura 3.2.

Si noti che nella Figura 3.2 la linea di regressione incrocia l'asse y con un valore di 2. Quindi a = 2. Si noti inoltre che per ogni aumento di 2 unità in x vi è un aumento corrispondente di 1 unità in y. Quindi Δy / Δx = 1/2 = 0, 5 = b. L'equazione di regressione diventa quindi
y = 2 + 0, 5x
Dato qualsiasi valore x, abbiamo una linea di regressione che ci consente di prevedere un punteggio, corrispondente ad esso. Ad esempio, se x fosse 8, allora
y = 2 + 0, 5 (8)
= 2 + 4
= 6
Riassumendo: Nel caso del predittore singolo, si calcola una linea retta che si adatta meglio ai punti osservati, dove il termine "miglior adattamento" significa che la somma delle deviazioni quadrate dei valori osservati attorno alla linea sarà minima.
Le formule necessarie per calcolare le costanti aeb che definiscono questa linea migliore sono dette formule "minimi quadrati" e sono le seguenti:

La formula per b è un rapporto tra la covarianza tra il predittore e il criterio e la variazione totale nel predittore. Quando la varianza del criterio e la varianza del predittore sono uguali, allora b = r, o la pendenza della retta di regressione è uguale al coefficiente di correlazione.

Due predittori:
È logico supporre che se il predittore X 1 può contribuire alla proficua previsione dei punteggi dei criteri e se il predittore X 2 può anche contribuire alla previsione corretta dei punteggi dei criteri, quindi utilizzare entrambi i predittori insieme dovrebbe consentire una previsione generale migliore rispetto all'utilizzo di entrambi predittore individualmente. Tuttavia, il grado in cui i due predittori (se combinati) miglioreranno la prevedibilità dipende da diversi fattori, la più importante delle quali è la correlazione tra i due predittori stessi.
Si consideri, ad esempio, la situazione in cui due predittori sono correlati sostanzialmente con un criterio ma non sono correlati tra loro, come segue:

Chiaramente, una grande quantità di varianza aggiuntiva dei criteri può essere spiegata usando il predittore 2 insieme al predittore 1. La relazione combinata tra due o più predittori e un criterio è chiamata correlazione multipla e ha il simbolo R. Come nel caso di r 2, il valore di R "rappresenta la quantità totale di varianza del criterio che può essere spiegata utilizzando diversi predittori. Quando i predittori 1 e 2 non sono correlati tra loro, il coefficiente di correlazione multipla al quadrato può essere mostrato come una funzione additiva dei singoli coefficienti di correlazione al quadrato, o
R 2 c . 12 = r 2 1c + r 2 2c (3.1)
Quindi, quando (l'intercorrelazione dei predittori) è zero, allora la validità multipla al quadrato è la somma delle validità individuali al quadrato.
Quando due predittori sono correlati tra loro, le cose diventano un po 'più complesse. Si consideri una situazione (come nel diagramma seguente) in cui ogni predittore ha una validità individuale sostanziale, ma dove r 12 è anche piuttosto grande.

A causa dell'interrelazione tra questi predittori, il diagramma mostra che la quantità di sovrapposizione tra predittore 2 e criterio può essere divisa in due parti: quell'area unica del predittore 2 e quell'area condivisa con il predittore 1. Quindi, l'uso di un secondo predittore in questa situazione ci consente di tenere conto di una maggiore varianza dei criteri rispetto a quella che si potrebbe fare usando il predittore 1 da solo, ma tutta la varianza del criterio prevista per 2 non è una nuova varianza. Pertanto è possibile affermare una regola generale relativa a più predittori.
A parità di condizioni, maggiore è la correlazione tra i predittori, minore sarà la previsione complessiva che verrà migliorata utilizzando entrambi i predittori. Il caso estremo, ovviamente, sarebbe la situazione in cui i predittori erano perfettamente correlati e non avremmo alcuna ulteriore variazione del criterio dovuta all'aggiunta del predittore 2 alla nostra batteria di selezione.

Nel caso di due predittori correlati l'uno con l'altro, possiamo esprimere R 2 in funzione delle diverse validità e della dimensione dell'intercorrelazione tra predittori con la formula 2
R 2 c . 12 = r 2 1c + r 2 2c - 2r 12 r 1c r 2c / 1 - r 2 12 (3.2)
si noti che se r 12 = 0, la formula 3.2 si riduce a
R 2 c . 12 = r 2 1c + r 2 2c
che è la formula 3.1.
Un'illustrazione più esplicita dell'influenza dell'intercorrelazione del predittore sulla dimensione dei coefficienti di correlazione multipla può essere ottenuta dalla Tabella 3.1, dove esempi di valori R e R 2 sono dati per coppie di predittori aventi validità di 0.30, 0.50 e 0.70 in condizioni ipotetiche di 0, 00, 0, 30 e 0, 6 intercorrelazione. La Figura 3.3 mostra l'andamento generale utilizzando i dati forniti nella Tabella 3.1. La morale dello psicologo è abbastanza evidente: evitare l'uso di predittori che sono altamente correlati l'uno con l'altro.

Equazioni di previsione:
L'equazione di previsione in una situazione con due predittori è un'estensione del modello predittore one. La forma generale dell'equazione è
y = a + b 1 x 1 + b 2 x 2 (3.3)
Questa è l'equazione per un piano anziché una linea retta. Per il lettore che ha familiarità con la geometria, la Figura 3.4 presenta un disegno tridimensionale delle relazioni tra le variabili x 1, x 2 e y corrispondenti all'equazione 3.3. Sono disponibili formule che consentono di calcolare le costanti a, b e che determinano il piano di regressione più adatto. Una volta che queste costanti sono state determinate, l'equazione risultante può essere utilizzata per fare previsioni sulle prestazioni dei criteri dei nuovi candidati di lavoro, dati i loro punteggi sui predittori separati.
Per illustrare, supponiamo che i dati siano disponibili su 100 uomini assunti per lavoro X durante un particolare mese che include punteggi in due test e dati dei criteri dopo un periodo di sei mesi. Questi dati possono essere analizzati per determinare i valori di a, b 1 e bi che meglio descrivono le relazioni tra le variabili.
Supponiamo che la seguente equazione fosse il risultato finale:
y = 2 + 0.5x 1 + 0.9x 2 (3.4)
Questa equazione dice che il punteggio di criterio più probabile per ogni nuovo noleggio sarà pari alla metà del suo punteggio nel test 1 più nove decimi del suo punteggio nel test 2 più due. Pertanto, se un nuovo richiedente ottiene un punteggio di 20 sul test 1 e 30 sul test 2, la sua prestazione prevista al termine di sei mesi dal momento dell'assunzione sarà
= 2 + 0, 5 (20) + 0, 9 (30)
= 2 -t-10 + 27
= 39
L'estensione del modello a due predittori a un modello di predittore di k, in cui k è un grande numero di potenziali pre-dizione del successo del lavoro, non è troppo difficile dal punto di vista concettuale. Il nostro modello si espande nella forma
y = a + b 1 x 1 + b 2 x 2 + b 3 x 3 + ... + b k x k (3.5)
Tuttavia, le procedure computazionali per la risoluzione dei valori dei minimi quadrati di tutte le costanti in tale equazione diventano piuttosto complesse a meno che non siano disponibili le strutture del computer. Il lettore è anche avvertito di ricordare che in tutte le discussioni precedenti c'è stata l'implicita assunzione di un mondo lineare, cioè tutte le relazioni tra coppie di variabili sono lineari. È possibile modificare il modello di regressione multipla per evitare questa ipotesi, ma ciò esula dallo scopo di questo libro.
moderatori:
Uno dei concetti più importanti nella teoria della selezione e del posizionamento è il concetto della variabile moderatore. A volte indicata come variabile di controllo della popolazione, una variabile moderatore può essere vista come qualsiasi variabile che, se variata sistematicamente, ha un effetto sulla grandezza della relazione tra due o più variabili.

Forse un esempio ipotetico (Figura 3.15) di come un moderatore potrebbe funzionare servirà a illustrare la sua influenza sul processo di selezione. Il grafico a dispersione superiore illustra una validità generale di 0, 50 tra il predittore e un criterio. Tuttavia, la "popolazione" rappresentata nella trama a dispersione è quella che include entrambi i sessi, cioè, sia gli uomini che le donne sono raggruppati insieme nel determinare la validità. Anche un'ispezione casuale della trama di dispersione superiore indica (se uomini e donne sono codificati diversamente come è stato fatto qui) che il modello di punteggi osservati per gli uomini differisce da quello osservato per le donne.
Per ottenere un'immagine più chiara di come differiscono esattamente, i due grafici a dispersione inferiore nella Figura 3.15 mostrano le relazioni del predittore-criterio separatamente per gli uomini e per le donne. Ora la differenza è sorprendente. Per gli uomini osserviamo una relazione altamente positiva, una che produce una validità di 0, 80. Per le donne, d'altra parte, vediamo che non esiste virtualmente alcuna relazione tra il predittore e il criterio. La validità per le donne è 0, 05.
La variabile moderatore nell'esempio precedente è, ovviamente, la variabile del sesso. La relazione tra predittore e criterio viene drasticamente influenzata dalla variazione del moderatore. La domanda "qual è la validità del mio predittore" diventa chiaramente più complessa. Ciò che inizialmente sembrava essere una validità moderatamente rispettabile si è ora trasformato in due valori distintivi ben distinti e separati: uno molto alto e uno molto basso.
Un nome per queste ultime validità potrebbe essere le validità condizionali, cioè la validità del predittore dato che la popolazione è composta da donne o dato che la popolazione è composta da uomini. Una caratteristica interessante delle variabili del moderatore è che un moderatore non deve avere alcuna relazione diretta con il predittore o la variabile di criterio (cioè, r ym e r im = 0).
Esempi di moderatori:
Esempi reali di moderatori sono stati trovati in una serie di indagini di ricerca. Vroom (1960), ad esempio, ha riscontrato effetti moderatori piuttosto marcati usando il grado di motivazione dei manager e dei supervisori di prima linea come variabile di moderazione. Tutti gli uomini studiati erano impiegati nello stabilimento di Chicago o New York di una società nazionale di servizi di consegna specializzata nella consegna di piccoli pacchi e pacchi da reparti e altri negozi al dettaglio a residenze private. I dati dello studio che meglio illustrano il concetto di moderatore sono riportati nella Tabella 3.4.

Tutti i supervisori sono stati divisi in tre gruppi in base al loro grado di motivazione valutato utilizzando un composito di diversi indici di motivazione ottenuti nella ricerca. Validità per un test di capacità di ragionamento non verbale sono state quindi ottenute per ciascuno dei quattro diversi tipi di valutazioni di supervisione di questi uomini.
Questo è stato fatto separatamente ad ogni livello di motivazione. Come mostra la Tabella 3.4, il test era apparentemente un predittore abbastanza valido di quanto un uomo sarebbe valutato dal suo supervisore se fossero considerati solo uomini con alta motivazione. Se modifichiamo sistematicamente la motivazione spostandoci verso i gruppi che hanno solo livelli di motivazione moderati o bassi, vediamo un corrispondente cambiamento sistematico nella relazione tra test e criterio. Minore è la motivazione del dipendente, minore è la validità del predittore, infatti le validità diventano addirittura negative per i gruppi a bassa motivazione.
Altri esempi di moderatori possono essere trovati negli studi di Dunnette e Kirchner (1960) e Ghiselli e dei suoi collaboratori (1956, 1960). Il lavoro di Dunnette e Kirchner è stato diretto principalmente all'identificazione dei moderatori legati al lavoro che raggruppa le persone in lavori simili in termini di responsabilità per ottenere la massima previsione all'interno di ciascun gruppo di lavoro.
Il metodo Ghiselli potrebbe essere definito un sistema moderatore "a variabili libere". Le persone vengono raggruppate semplicemente sulla base del modo in cui il loro successo può essere previsto senza alcun riferimento diretto a nessuna variabile esterna. Fredericksen e Gilbert (I960) hanno anche svolto ricerche sui moderatori per determinare il grado in cui l'effetto di un moderatore è probabile che sia coerente nel tempo. Scoprirono che un moderatore identificato in uno studio del 1954 (Fredericksen e Melville, 1954) stava ancora operando nel follow-up del 1960.
Teoria della selezione moderna e tradizionale:
Forse il concetto della variabile moderatore illustra meglio la tendenza del modem nell'enfasi sulla selezione e sul posizionamento. Tradizionalmente, la selezione e la convalida sono stati problemi che sono stati considerati come la soluzione migliore semplicemente stabilendo un criterio che sembrava affidabile e un predittore che poteva meglio prevedere quel criterio.
L'enfasi era quasi del tutto sull'istituzione di un'alta validità con poco o nessun pensiero verso l'esplorazione delle molte variabili addizionali che, quando variate, potevano aggiungere o sottrarre dalla correlazione ottenuta. Il motto generale che troppo spesso sembrava connotare la metodologia di selezione era lo slogan "Se funziona, usalo!"
Senza dubbio, questa politica è stata responsabile di sviluppi molto diversi nella psicologia industriale. Innanzitutto, probabilmente ha contribuito al grado in cui gli psicologi sono stati accettati nell'industria. La gestione è generalmente orientata verso risultati positivi come rappresentato da una migliore selezione e non è eccessivamente preoccupata di come è realizzata.
Sfortunatamente, tuttavia, questo orientamento è probabilmente anche responsabile del fatto che le validità nella previsione non sono aumentate sostanzialmente (se non del tutto) negli ultimi 50 anni - un commento piuttosto inquietante sugli sforzi degli psicologi impegnati in questo tipo di lavoro.
In una recensione del 1955 di un gran numero di studi di validità, Ghiselli (1955) ha indicato che è davvero un evento insolito ottenere un coefficiente di validità di 0, 50 o migliore. La Figura 3.16 presenta le distribuzioni di frequenza presentate da Ghiselli su coefficienti di validità di grandezze variabili per diversi tipi di lavori. Si noti che solo nella distribuzione delle validità per gli impiegati con test di intelligenza come predittori e misure di competenza come criteri ci sono un numero elevato di validità superiore a 0, 50.

L'attuale interesse per i moderatori è rappresentativo di un approccio più ampio e un po 'più sofisticato verso la selezione. Si può risalire a quando Toops (1948) fece appello agli psicologi per considerare la possibilità che stratificando sistematicamente le persone (ad esempio i lavoratori) in base alle variabili personali, si dovrebbe essere in grado di migliorare la previsione. Il suo metodo di classificazione, che ha definito la procedura di aggiunta, è il precursore dei moderatori.
Modello di selezione di Dunnette:
Forse l'attuale visione della metodologia di selezione può essere meglio rappresentata dal modello di selezione proposto da Dunnette (1963). Questo modello è mostrato nel diagramma presentato in Figura 3.17 ed è progettato per indicare il labirinto di complessità e interrelazioni che esistono nella situazione di selezione. Il modello può essere considerato più che un tentativo di indicare semplicemente la natura dinamica della selezione, ma rappresenta anche una richiesta per gli psicologi di sfruttare queste dinamiche e utilizzarle al meglio per migliorare la prevedibilità.

Si può probabilmente comprendere il punto di vista rappresentato dal modello in termini della descrizione esatta usata da Dunnette (1963, p 318):
Si noti che il modello di predizione modificato tiene conto delle interazioni complesse che possono verificarsi tra predittori e varie combinazioni di predittori, diversi gruppi (o tipi) di individui, diversi comportamenti sul lavoro e le conseguenze di questi comportamenti rispetto agli obiettivi dell'organizzazione . Il modello consente la possibilità che i predittori siano differenzialmente utili per predire i comportamenti di diversi sottoinsiemi di individui.
Inoltre, mostra che comportamenti di lavoro simili possono essere prevedibili da modelli di interazione abbastanza diversi tra gruppi di predittori e individui o anche che lo stesso livello di prestazioni sui predittori può portare a modelli di comportamento del lavoro sostanzialmente diversi per individui diversi. Infine, il modello riconosce la noiosa realtà che comportamenti di lavoro uguali o simili possono, dopo aver attraversato il filtro situazionale, portare a conseguenze organizzative abbastanza diverse.
L'attuale tendenza nella selezione rappresentata dalla consapevolezza dei moderatori e dal modello di selezione di Dunnette dovrebbe comportare progressi sia nella maggiore efficienza della selezione che nel grado di comprensione delle dinamiche della previsione accurata.
Variabili soppressore:
Nessuna discussione sulla selezione sarebbe completa senza alcuna menzione delle variabili soppressore. In un certo senso una variabile soppressore è simile a una variabile moderatore in quanto è definita come "una variabile che può avere un effetto sull'entità di una determinata relazione predittore-criterio anche se ha poca o nessuna relazione con la variabile criterio stessa. ”

La dinamica di una variabile soppressore nella predizione può essere meglio compresa rivedendo il concetto di una correlazione parziale e la sua misura correlata, la correlazione semi-parziale. Se si avevano due predittori e un criterio che era correlato come mostrato qui, allora la correlazione parziale tra il criterio e il predittore x, che è r 1c. 2, è stata definita come la correlazione tra x 1 e C dopo che gli effetti di x 2 sono stati parzializzati da entrambi, quindi

Supponiamo di voler rimuovere gli effetti di X2 dal criterio prima di calcolare la correlazione. Tale correlazione è chiamata una correlazione semi-parziale o parziale. Ad esempio, potremmo essere interessati alla correlazione tra i punteggi dei test di intelligenza (il nostro predittore x 1 ) e il livello di abilità finale alla fine di un programma di formazione sulla tipizzazione (il criterio) x 2 potrebbe rappresentare il livello di abilità iniziale di tutti i dipendenti in termini di la loro velocità di battitura prima di seguire il corso di formazione. Pertanto, vogliamo rimuovere gli effetti del livello di abilità iniziale sulla performance finale prima di calcolare la validità del nostro test di intelligenza.
La nostra correlazione semi-parziale diventa ora:

Il meccanismo di una variabile soppressore è identico a quello mostrato sopra ad eccezione di (1) in generale, la variabile x 2 ha solo una leggera (eventuale) relazione con il criterio e (2) uno è interessato a rimuovere i suoi effetti dal predittore x 1 .
La situazione generale può quindi essere schematizzata come:

Non è possibile prevedere con assoluta certezza se le correlazioni parziali o semi-parziali saranno maggiori o minori della semplice correlazione esistente tra le variabili, poiché la dimensione sia del numeratore che del denominatore è influenzata dal processo di parzializzazione. L'unica volta che non lo è è quando la variabile che viene parzializzata è solo correlata a una delle due altre variabili, come nel caso del soppressore. In una situazione del genere viene successivamente influenzato solo il denominatore (la varianza viene rimossa) e la correlazione semi-parziale risultante è maggiore della semplice correlazione non parzializzata tra le variabili.
Convalida incrociata:
Una caratteristica della maggior parte dei sistemi di selezione di predizione multipli è che nel loro sviluppo si tende tipicamente a capitalizzare la variazione casuale esistente nel campione di impiegati utilizzati per scopi di convalida. Ciò è particolarmente vero con il modello di regressione multipla ma si applica anche alla procedura di interruzione multipla. Poiché il modello di regressione multipla ha proprietà minime, ovvero, deliberatamente riduciamo al minimo gli errori nel predire il nostro particolare campione, è probabile che se applichiamo la nostra equazione a un nuovo campione (dalla stessa popolazione) non troveremo la nostra previsione efficiente come prima.
Pertanto, il nostro R 2 calcolato è una sovrastima di ciò che la futura validità del nostro sistema di previsione è suscettibile di essere, poiché l'utilizzo della nostra equazione ai fini della previsione implica automaticamente l'applicazione a nuovi campioni di lavoratori. Questo calo atteso in R 2 è noto nelle statistiche come il problema del restringimento e può essere meglio illustrato esaminando la Figura 3.18.
Nella Figura 3.18 abbiamo due campioni di individui. Ciascuno rappresenta un campione casuale estratto o appartenente alla stessa popolazione. Ad esempio, il campione A potrebbe rappresentare tutti i candidati di lavoro per il lavoro X durante i mesi dispari e il campione B potrebbe rappresentare tutti i candidati di lavoro durante i mesi pari di un determinato anno.
Sarebbe molto insolito, anche con un numero molto elevato di candidati in ciascun campione, che i due campioni siano identici in termini di grafici a dispersione. Poiché è possibile che i loro diagrammi di dispersione varieranno a causa dell'errore di campionamento, ci si può aspettare che la correlazione tra il predittore e il criterio (validità) vari in qualche modo, così come l'equazione di regressione calcolata su ciascun campione.
Supponiamo di aver preso l'equazione di regressione calcolata sul campione A e di usarla per predire i punteggi del campione B. Ovviamente non potremmo fare un buon lavoro nel ridurre al minimo l'uso della linea A con il campione B, dato che potremmo usare la linea di regressione B, dopo tutto, la linea B per definizione minimizza Σd 2 per quel campione. Qualsiasi altra linea avrà quindi un errore più grande associato ad essa. Quindi R 2 deve essere ridotto corrispondentemente.
Sono disponibili formule per stimare la quantità di restringimento che ci si può aspettare quando si utilizza questa equazione su un nuovo campione. Una tale formula è
R 2 8 = 1 - [(1 - R2) n-1 / n - k - 1]
Dove
R 2 = correlazione multipla rattrappita al quadrato
R 2 = quadratura multipla correlata ottenuta dal campione di validazione
n = numero di persone nel campione di validazione
k = numero di predittori nell'equazione di regressione
È meglio, tuttavia, convalidare l'equazione incrociando un secondo campione e provarlo per vedere quanto bene prevede. Se sembra che ci sia una goccia molto grande, si potrebbe voler rivedere l'equazione (magari combinando entrambi i campioni in un gruppo). Il grande restringimento si trova più spesso quando le dimensioni del campione sono piccole e / o il numero di predittori è grande rispetto alla dimensione del campione.
Mosier (1951) ha discusso un certo numero di tipi di convalida incrociata che possono essere condotte a seconda del progetto dello studio e se si è interessati a generalizzare solo a un nuovo campione o se si vogliono generalizzazioni più ampie che concertano l'equazione di previsione (per esempio, a diversi sessi, diversi criteri, ecc.). Il primo è chiamato un caso di generalizzazione della validità; il secondo è un caso di estensione della validità. Ovviamente, ci si aspetterebbe un restringimento maggiore in quest'ultimo caso e la formula 3.9 su% si applica ai casi di generalizzazione della validità.